
Why We Need to Build, Baby, Build
AI for DC


Hi
Welcome (back) to The Prompt. AI isn’t well understood, but we learn a lot in our work that can help. In this newsletter, we share some of those learnings with you. If you find them helpful, make sure you’re signed up for the next issue. You have choices here – to receive our weekly US newsletter, our monthly EU newsletter, or if you really want to load up, then both.

[Insight] Democratic AI at Speed
Entrepreneur Jared Isaacman recently pointed out that China is now installing 93 gigawatts (GW) of solar capacity every month—compared with just 56 GW added in the US in all of 2023. This is what state-led industrial mobilization looks like: the ability to create demand by fiat and, when paired with accurate foresight, actually shape the global supply chains of the future.
The democratic model for industrial mobilization has a different kind of superpower—one grounded in openness, individual creativity, and the decentralized demand signals that come from a vibrant user base. That’s the foundation on which we’re building at OpenAI.
Today, we announced that we’re expanding our Stargate project with partner Oracle to deploy an additional 4.5 GW of AI infrastructure in the US, bringing our total data center capacity under development in the US to more than 5 GW – halfway to our goal of 10 GW of AI infrastructure before 2030. We estimate that building, developing, and operating this additional 4.5 GW of capacity will create more than 100,000 US jobs in construction, operations and all along the supply chain.
Also building AI infrastructure through the democratic model, the Trump Administration’s coming AI Action Plan is expected to outline strategies to modernize the grid, streamline permitting, and generate more energy to power the data centers AI requires. In March, we submitted suggestions to help inform the Administration’s plan on infrastructure, national security, energy and the freedom to innovate and learn.
We are witnessing, in real time, a contest between political-economic systems for global leadership in AI—the state-directed authoritarian model vs. the democratic/private-sector model, where people and institutions are the primary builders.
Our more than 500 million active users are generating the demand. Now we must move with urgency to meet it—because the window to shape this future is closing fast. – Ben Schwartz, Managing Head of Infrastructure Policy and Partnerships

[Data] DeepSeek’s autocratic outputs
As a reminder of the stakes for continued US leadership on AI—we’re building a benchmark for measuring LLM outputs in both English and simplified Mandarin for alignment with CCP messaging. Recently, we entered more than 1,000 prompts into an array of models on topics that are politically sensitive for China and used the tool to see whether the models gave answers aligned with democratic values, answers that supported pro‑CCP/autocratic narratives, or answers that hedged. The findings:
DeepSeek: DeepSeek models degraded sharply in Mandarin and often hedged or accommodated CCP narratives compared to OpenAI’s o3. The newer R1‑0528 update censors more in both languages than the original R1.
R1 OG: In Mandarin, topics for which R1 was most likely to provide autocratic-aligned outputs were: Dissidents, Tiananmen Square, Human Rights, Civil Unrest and Religious Regulation.
R1-0528: The most recent update to R1 showed similar results. Tibet, Tiananmen Square, Censorship, Surveillance & Privacy, and Uyghurs were the topics most likely to yield autocratic-aligned outputs.
Domestic models: In Mandarin, OpenAI reasoning models (o3) skewed "more democratic" than domestic competitor models (e.g., Claude Opus 4, Grok 3, Grok 4). In English, all domestic models performed similarly.
Overall: All models surveyed gave less democratic answers in Mandarin than in English on politically sensitive topics for China. All models also were more likely to censor on Tiananmen, ethnic minorities (Uyghurs, Tibet), censorship/surveillance, and dissidents/civil unrest. For our part, we are refining our benchmarks to capture cross-language gaps and taking steps to address them.

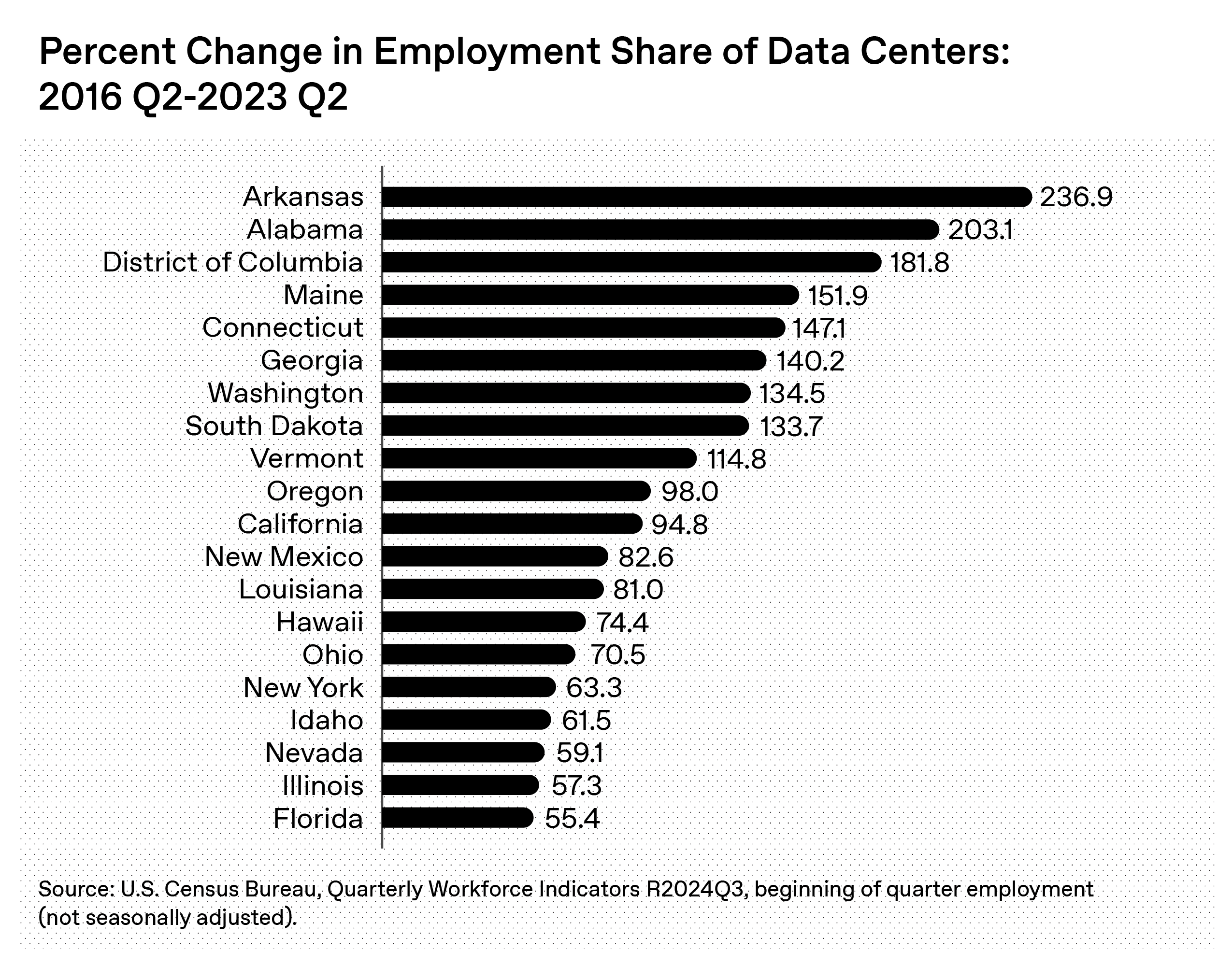
[AI Economics] Tracking data center jobs
How many overall jobs have data centers actually created? And who gets them? According to the US Census Bureau, US data center employment has grown by more than 60% in the last several years – from roughly 300,000 workers in 2016 to over 500,000 in 2023. The average salary for these half million data-center workers is over $110,000.
But there’s variation in the states that have seen the most data-center growth, with states like Arkansas, Alabama and Maine seeing the largest percentage growth since 2016, while other states (like Rhode Island, Delaware and Nebraska) have decreased.
And while many think only of software engineers and project managers when they think of data, most of the employment impact from data centers—91% of it—comes during construction, and includes technicians, electricians, and security personnel. – Rachel Brown and Cassandra Duchan Solis, Economic Research

[Prompt] What >2.5 billion prompts per day mean
Being The Prompt, we’re obliged to point out that a new OpenAI analysis finds ChatGPT users send more than 2.5 billion prompts to the platform each day, including more than 330 million per day in the US. What kind of economic impact does that create? For a robust answer, check out our new Economic Research team’s analysis here.
But for fun, we also asked ChatGPT for its answer:

[Event] What investing in talent means to us
We believe that how a company treats and invests in talent reflects its values and character. At OpenAI, we invest in talent by cultivating it. So maybe you want to join us? This Thursday, Joaquin Quinonero Candela, the head of recruiting at OpenAI, will discuss his approach in an OpenAI Forum talk, “Careers at the Frontier: Hiring the Future at OpenAI.” We’ve received more than 10,000 RSVPs so far (!!!), and we’d love to see you there, too.

8:00 PM – 9:50 AM ET on Jul 25

[Disclosure]
Graphics created by Base Three using ChatGPT.